TL;DR: I can now modify my sinscape.js script file and when I do the sine-wave based voxel landscape will automatically refresh in the engine without a restart.
I wanted to add "hot reloading" to the engine so that changes to data files are automatically reflected in the running engine. This is one of those small developer-ergonomics changes that, over time, I believe has huge benefits to productivity.
The primary challenge was to architect this such that the engine internals remain clean: i.e.
- Avoid scattering with knowledge of source file to asset mappings throughout the engine
- Avoid introducing complex inter-object references within the engine (makes for a Rust lifetime manageable headache)
- Minimal runtime impact in a release build
- Keep file watching code isolated and independent as it's a development feature, not an engine feature
I expect to have to revist this as the engine functionality increases and as I learn more about how to use Rust more effectively. 😄
This article does not go into full depth on some of changes discussed. If you'd like more detail added to any section, let me know! I wanted to be sure there was an audience for this before going into any more depth.
Architecture
- Build a list of files -> asset ids during loading
- Add a dev-only Actor that watches for file change
- Trigger a reload for any assets that have been marked dirty
- Do the reload
Build the dependency graph during scene loading (DependencyList)
Record the dependencies
As the loader opens files, it maintains a mapping of each file to the list of asset ids that file impacted. Building the "graph" is simple as long as two rules are followed:
- Record direct dependencies: whenever a file is opened, ensure any assets created by that file add any entry mapping that
file -> asset id
- Record transitive dependnecies: whenever an asset relies on data from another asset, copy all the dependencies from the existing asset to the newly created asset.
Example: when loading a .vox file, we simply add that file name as a dependency on the model that's going to use that vox data.
dependency_list.add_model_entry(vox_file.to_str().unwrap(), &desc.header.id);
let vox_data: vox_format::VoxData = vox_format::from_file(vox_file).unwrap();
We record the dependencies as IDs rather than object references as it's far cleaner for managing lifetimes.
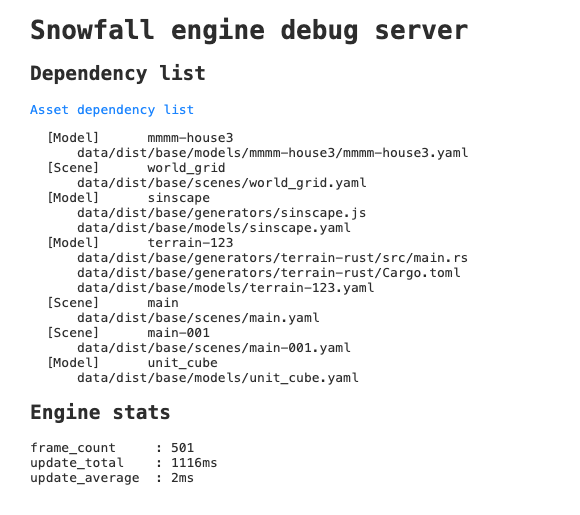
For a simple scene, we end up with a list like the following
1.4 INFO --- Dependency list ---
[Model] mmm-house3
data/dist/base/models/mmm-house3/mmm-house3.yaml
data/dist/base/models/mmm-house3/obj_house3.vox
[Model] sinscape
data/dist/base/generators/sinscape.js
data/dist/base/models/sinscape.yaml
[Model] unit_cube
data/dist/base/models/unit_cube.yaml
[Scene] main
data/dist/base/scenes/main.yaml
[Instance] house-000
data/dist/base/models/mmm-house3/mmm-house3.yaml
data/dist/base/models/mmm-house3/obj_house3.vox
data/dist/base/scenes/main.yaml
[Scene] main-001
data/dist/base/scenes/main-001.yaml
Intrusive tracking
This is an "intrusive" approach: the bookkeeping of dependency tracking must be inlined directly into the loading logic and cannot be plugged in as an optional feature. This however feels fine as a design choice since the cost of building a mapping table is relatively low and it is conceptually simple.
The loading code expects each asset load to have 1 or more calls to methods such as the below. Thus, we want an interface that makes recording dependencies simple, hard-to-get-wrong, and ideally self-descriptive one-liners.
impl DependencyList {
pub fn add_scene_entry(&mut self, file_path: &str, id: &str) { ... }
pub fn add_model_entry(&mut self, file_path: &str, id: &str) { ... }
pub fn add_instance_entry(&mut self, file_path: &str, id: &str) { ... }
pub fn copy_entries(&mut self,
src_type: EntityType, src_id: &str,
dst_type: EntityType, dst_id: &str) { ... }
Design choice: a list not a graph
Transitive dependencies copy dependencies which flattens the dependency graph. This makes it a dependency list. This is done for simplicity's sake, though has a small trade-off (continue reading for more on this).
The alternative would be to record asset -> asset dependencies as well file -> asset dependencies. This would add only a little more complexity as the flattening would happen at use, not build, time for the list -- but per the below this didn't seem worth doing at this stage. 🤷
Design choice: an immutable list after initialization
The architecture builds this list at initial load only. It is treated effectively an immutable/static list after startup.
✅ The benefit is this is very simple to reason about. The dependency list requires no dynamic update logic.
🚫 The downside is changes such as file renames or inter-asset dependency modifications will cause the dependency list to go stale.
The trade-off seems good as the unsupport cases are not the common case, the workaround is trivial (restart the engine).
Watch the files for changes (FileWatcher)
I wanted to keep file watching logic out of the core engine. From an architectural perspective this should be as "pluggable" feature while incurring as little effect on the runtime in a release build as possible.
- The overhead of building the
DependencyList during loading seems fine to always in the build
- The notion of a
DirtyList also seems fine in a release build as it is rather isolated
- However, the file watching code should not be in the core code.
This was solved by adding an Actor to the Engine. This approach is quite simple and encapsulates the file watching code quite nicely. The FileWatcher itself only depends on a file list and file -> id mapping table: it doesn't really need to understand much more than doing that mapping.
Pseudo-code
on init:
for each file in the dependency list
set up a file watcher
on every Nth frame update:
check if the file watcher has reported any changes
if no, return
for each modified file
look up the asset ids dependent on that file
update the engine's dirty_list with those asset ids
Rust code
Details
This is certainly not the "best" code, but was good enough to get things working. I'm still learning Rust, so feedback on improving this code is very welcome.
use crate::engine;
use log::info;
use std::{
collections::HashSet,
sync::{Arc, Mutex},
};
use notify::{Config, PollWatcher, RecursiveMode, Watcher};
pub struct FileWatcher {
watcher: PollWatcher,
dirty_list: Arc<Mutex<HashSet<String>>>,
}
impl FileWatcher {
pub fn new(file_list: Vec<String>) -> Self {
let (tx, rx) = std::sync::mpsc::channel();
let mut watcher = PollWatcher::new(tx, Config::default().with_manual_polling()).unwrap();
let mut file_list = file_list;
file_list.sort();
for f in file_list {
info!("Watching: {:?}", f);
watcher
.watch(f.as_ref(), RecursiveMode::NonRecursive)
.unwrap();
}
let dirty_list = Arc::new(Mutex::new(HashSet::new()));
{
let dirty_list = dirty_list.clone();
std::thread::spawn(move || {
for res in rx {
match res {
Ok(event) => {
let mut v = dirty_list.lock().unwrap();
for p in event.paths {
v.insert(p.to_str().unwrap().to_string());
}
}
Err(e) => println!("watch error: {:?}", e),
}
}
});
}
Self {
watcher,
dirty_list,
}
}
}
impl engine::Actor for FileWatcher {
fn update(&mut self, frame_state: &engine::FrameState) {
if frame_state.frame % 60 != 37 {
return;
}
self.watcher.poll().unwrap();
let mut v = self.dirty_list.lock().unwrap();
if v.len() == 0 {
return;
}
let values = v.drain();
for file in values {
info!("File changed: {:?}", file);
let entries = frame_state.dependency_list.entries_for_file(&file);
for e in entries {
frame_state.dirty_list.borrow_mut().push(e.clone());
}
}
}
}
Communicate what's changed (DirtyList)
The Engine maintains a simple DirtyList to be notified about changes.
I wanted to avoid complex event system, callbacks, object references or anything of that sort. So it simply has a list of asset ids that are currently considered "dirty."
The FileWatcher, on it's own file events, simply adds assets ids to this list.
On each frame, the Engine checks if the dirty list is non-empty. If so, it provides the hot reloader with the list of asset ids to reload (and the original DependencyList to do the back-mapping to files it may need to reload). It clears the list after telling the hot reloader to do its work.
Reload the asset (HotReloader)
The HotReloader uses a brute-force implementation (this likely will need to be revisted in the future).
If anything needs to be reloaded, the hot reloader loads the entire scene from disk again. This has the advantage of being simple: it's a "clean slate" that uses the exact same logic as engine startup.
It then loops over all active entities in the engine and checks if they are in the dirty list. If they are, it copies in the relevant data from the freshly loaded scene over the current data -- thus refreshing the asset.